

一、场景描述
客服助手、智能助理等场景下,其实可能有大量的问题是重复的,这些问题有确切的答案(例如没有时效性的内容、确定的检索答案),这时可以收集起来复用,能够加快检索速度+减少token消耗。
效果:
显著提升响应速度和用户体验:
减少检索时间: 当用户提出一个已知重复问题时,系统可以直接从预设的知识库或问答库中调取标准答案,而不是每次都重新进行复杂的语义理解、信息检索或推理计算。这大大缩短了生成回答的时间。
提高交互效率: 用户能更快地得到准确答复,减少了等待时间,提升了满意度和使用体验。对于高频问题,这种效率提升尤为明显。
降低计算资源和Token消耗:
减少模型计算量: 避免了重复RAG(检索增强生成)或纯生成过程,节省了GPU/TPU等硬件资源。
节省Token使用: 在生成式AI模型中,Token是计费和计算资源消耗的基本单位。复用标准答案意味着减少了需要处理和生成的Token数量,特别是在处理长答案时,节省效果更显著。这对于控制成本、优化模型运行效率至关重要。
第一次提问:耗时较长
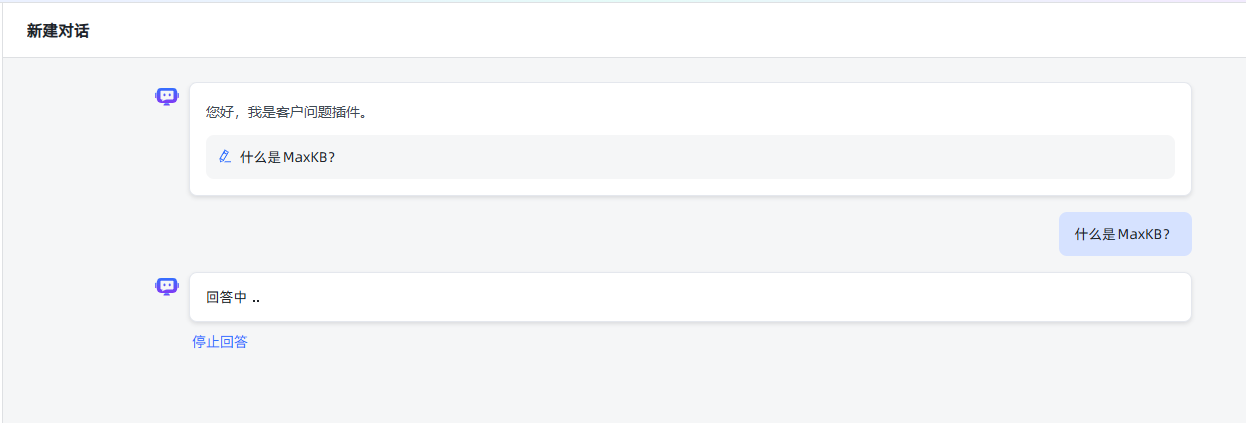
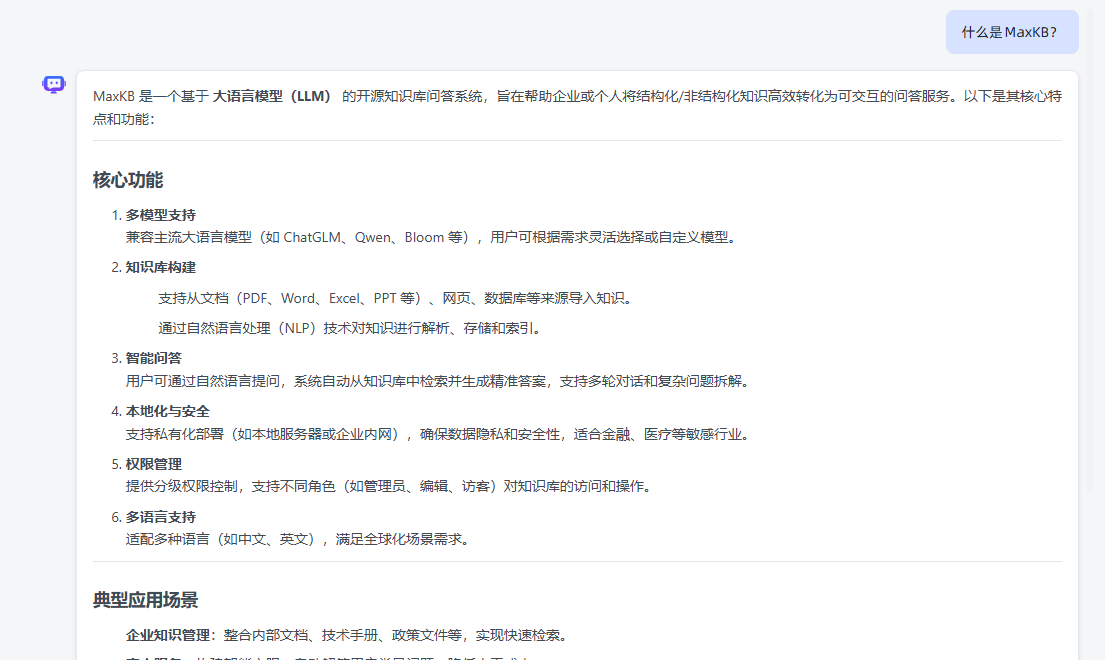
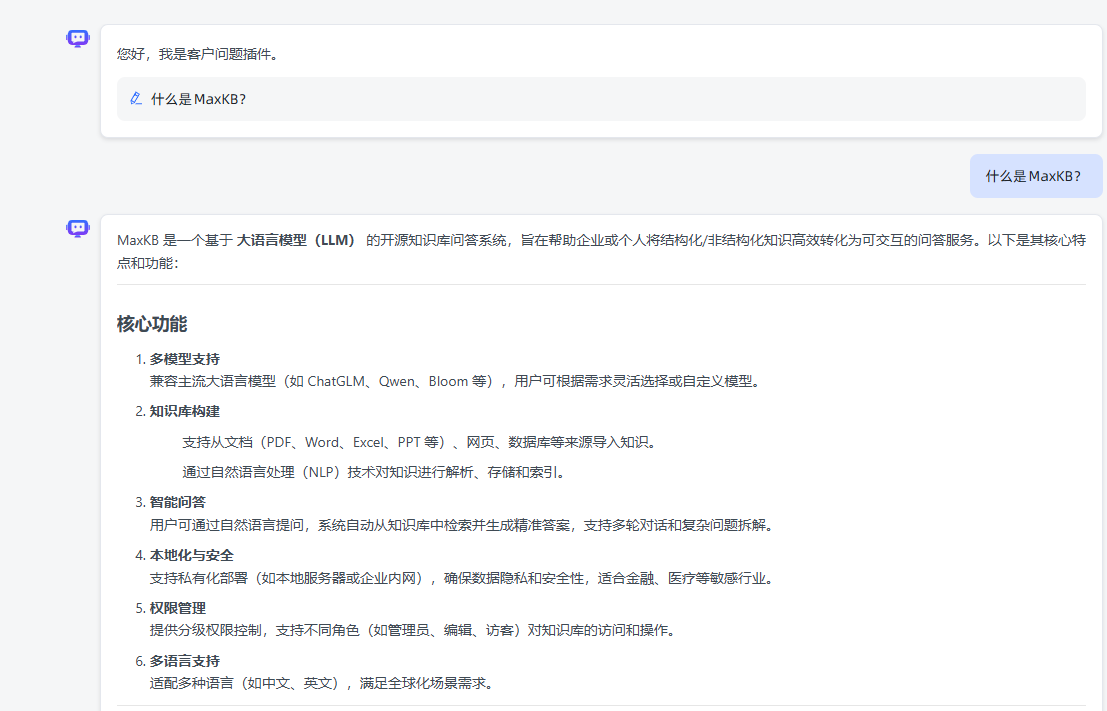
新建对话,再次提问:
秒级回答。
二、实现
创建知识库,创建空白文档:
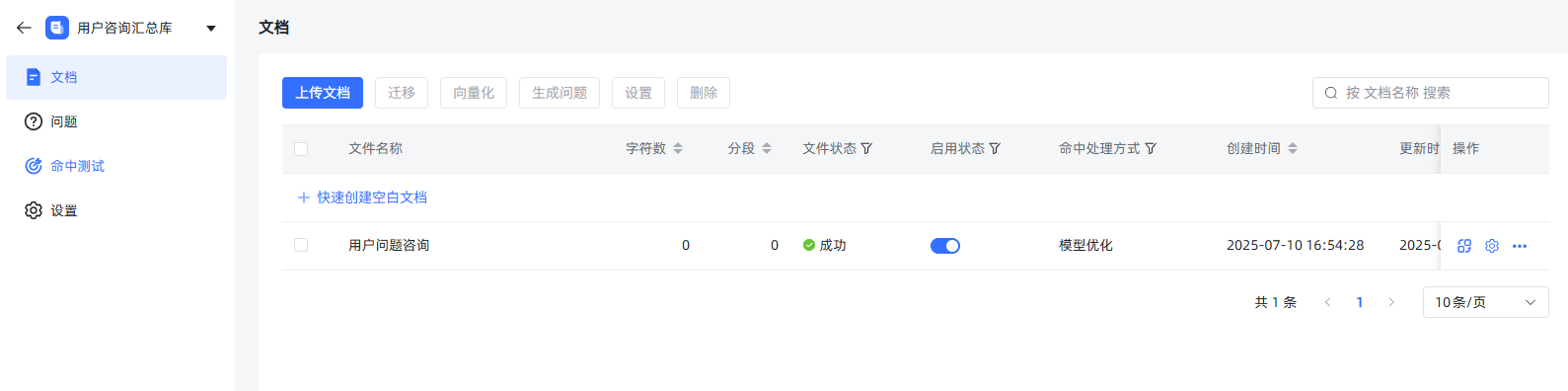
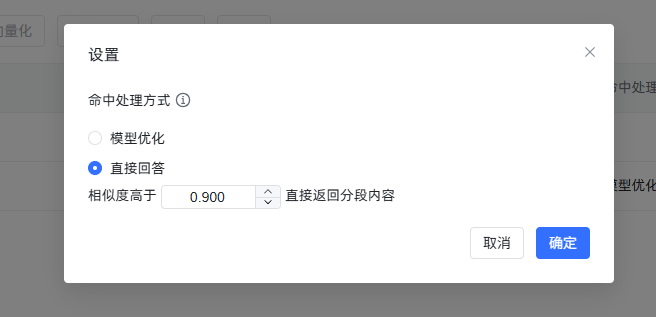
设置直接回答(按需)
创建函数库:
import requests
def recvques(question, answer):
"""
接收问题并处理答案的函数。
参数:
question (str): 提出的问题。
answer (str): 对问题的回答。
返回:
None
"""
# 模拟处理数据
data = {
"problem_list": [
{"content": question}
],
"title": question,
"content": answer
}
# 定义请求URL和请求头
url = "https://east-mk.fit2cloud.cn/api/dataset/181dd7ec-5d6b-11f0-a5ea-0242ac180003/document/7cdf3a9a-5d6b-11f0-8d56-0242ac180003/paragraph"
headers = {
'accept': 'application/json',
'AUTHORIZATION': 'user-cc392db28e70a3f4783112bd5470388c'
}
try:
response = requests.post(url, headers=headers, json=data)
if response.status_code == 200:
return response.json()
else:
return f"Failed to send request. Status code: {response.status_code}"
except Exception as e:
return f"Error sending request: {e}"创建知识库,检索上述的知识库,判断是否为空,为空继续自己的工作流,且在最后上传问题+答案,不为空直接返回。
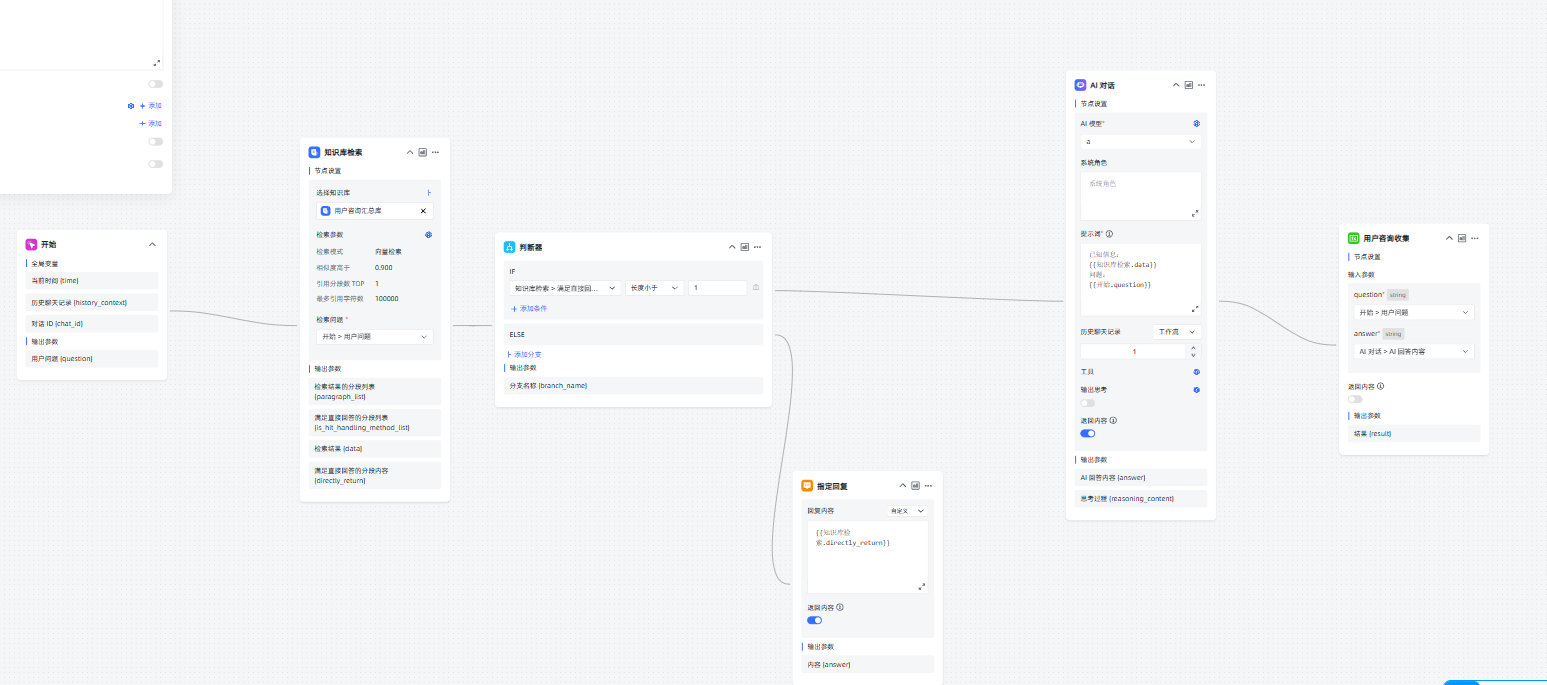
通过这样,可以对非时效性的工作流实现每次收集重复问题,快速响应。
派生:时效性的可以给个过期参数,超时删除分段。
在对话记录里面,也可以选择优质回答,编辑后入该库,以进一步提高检索效果。