一、场景 版本:v1.10.10 场景: (1)需要释放并发限制,提高吞吐 (2)提高cpu资源利用率、内存利用率 (3)用户访问量大,访问卡顿,需提高用户的体验,且保证服务的可用 二、解决办法 升级版本 尝试升级。新版 1.10.11 的加载逻辑将有优化,可提高访问速度。
一、场景
版本:v1.10.10
场景:
(1)需要释放并发限制,提高吞吐
(2)提高cpu资源利用率、内存利用率
(3)用户访问量大,访问卡顿,需提高用户的体验,且保证服务的可用
二、解决办法
升级版本
尝试升级。新版 1.10.11 的加载逻辑将有优化,可提高访问速度。
提高服务器配置
为保障系统稳定运行及良好的用户体验,需针对性提升核心硬件配置,提高 CPU 、内存、带宽等。推荐最低采用 4 核 CPU + 8GB 内存 的硬件组合,该配置可满足中小规模业务低并发场景下的基础运行需求,并发较大时,配置也需相应增加。
设置worker数
为优化系统处理能力,可通过调整 worker 进程数量来匹配服务器性能,具体配置方式如下:
在安装部署之后,在 /opt/maxkb 目录下面,找到 docker-compose.yaml 文件,适当提高 worker 数。(注意不要过高,大于等于2*cpu核心数+1时会让cpu拉满,以需求和实测情况调整)
cd /opt/maxkb
vi docker-compose.yaml

设置 PGSQL 内存在 /opt/maxkb目录下找到 docker-compose-pgsql.yml 文件,按需设置 mem_limt 。如 300 并发时,可使用2-4G内存。 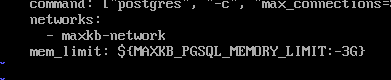
设置 max_connections 数为保障高并发场景下的数据库连接稳定性,需合理设置 PostgreSQL 的最大连接数,具体配置方式如下: 在 /opt/maxkb/data 找到 postgresql.conf 文件,找到max_connections配置项,根据实际并发需求设置 max_connections 。如 300 并发时,设置为2000。 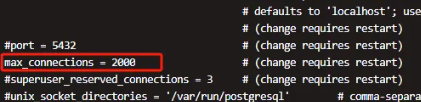
设置线程池数(版本1.9+)针对提升系统并发处理能力,建议针对线程池进行如下配置(适用于版本 1.9 及以上): 编辑项目根目录下的 .env 配置文件,新增或修改以下参数: docker exec -it pgsql bash
psql
# 查看最大连接数
show max_connections;
# 改.env的配置
# 数据库连接池最大溢出数,根据服务器CPU核心数和业务并发量调整
MAXKB_DB_MAX_OVERFLOW=80
MAXKB_DB_MAX_OVERFLOW 用于设置数据库连接池的最大溢出连接数(超出核心连接数的临时连接),合理设置可提升高并发场景下的数据库访问效率。
数值并非越大越好,过度设置可能导致数据库连接耗尽,建议结合监控工具观察连接使用情况动态优化。 使用主从 pgsql ,缓解并发压力为进一步提升系统并发处理能力,建议采用 PostgreSQL 主从架构部署,将数据库与应用服务分离,通过读写分离分散压力。服务增配的同时,可根据读压力横向增加从库数量,灵活应对业务增长,写操作集中在主库,读操作分散到从库,降低单库负载。 重启改完后,重启服务. mkctl reload
其他可选项pgsql 参数调优:当数据库成为并发瓶颈的原因时,重点考虑最大连接数、内存等因素。可进一步考虑细节参数的调整。 # 强制把 PGSQL 数据同步更新到磁盘,如果系统的IO压力很大,比如应用上传图片、文件数量多、知识库更新频繁,把改参数改为off
# 如果测试发现主要的瓶颈就在系统的IO,如果需要减少IO的负荷,最直接的方法就是把fsync关闭,但是这样就会在掉电的情况下,可能会丢失部分数据。
fsync
# 在PostgreSQL数据库中,max_wal_size是一个重要的配置参数,它指定了两个检查点(checkpoint)之间,WAL(Write-Ahead Logging)可以增长的最大大小。这个参数的默认值是1GB。增加max_wal_size的值可以提高数据库性能,因为它允许在自动检查点之间积累更多的WAL数据,但这也意味着会消耗更多的磁盘空间,并可能延长数据库崩溃恢复所需的时间。
max_wal_size = 1GB
# max_worker_processes 数据库系统可启动的最大后台进程数,默认 8。需大于 max_parallel_workers_per_gather + 其他后台进程(如 autovacuum)
# max_parallel_workers_per_gather 单个查询可启动的最大并行工作进程数,默认 4。
nginx 开启 gzip 压缩适用于对一些静态文件的加载速度优化: 注:实际中按实际情况来调整下列参数 vi /etc/nginx/nginx.conf
http {
# 开启gzip压缩
gzip on;
# 设置压缩级别,1-9,级别越高压缩率越高但消耗CPU资源也越多.建议设置为 5,平衡压缩率和 CPU 消耗
gzip_comp_level 5;
# 设置压缩的最小文件大小,小于此值的文件不压缩。因为过小的文件压缩收益有限,反而可能因压缩开销影响效率。
gzip_min_length 1k;
# 设置压缩缓冲区大小
gzip_buffers 4 16k;
# 设置压缩版本(默认1.1,前端如果是squid2.5请使用1.0)
gzip_http_version 1.1;
# 设置压缩类型,对哪些类型的文件进行压缩
gzip_types text/plain text/css application/json application/javascript text/xml application/xml application/xml+rss text/javascript application/vnd.ms-fontobject application/x-font-ttf font/opentype image/svg+xml image/x-icon;
# 是否在http header中添加Vary: Accept-Encoding,建议开启
gzip_vary on;
# 禁用IE 6 gzip
gzip_disable "MSIE [1-6]\.";
# 其他原有配置...
}
systemctl reload nginx
# 或
service nginx reload
开启后,Nginx 会自动对指定类型的文件进行压缩,减少网络传输数据量,提高网站加载速度。可以通过浏览器开发者工具的 Network 面板查看 Response Headers 中是否有Content-Encoding: gzip来验证是否生效。 三、调试调试阶段核心目标是通过监控关键指标、执行并发测试,验证前期配置(硬件、线程池、主从库、worker 数、连接数)的有效性,及时定位资源瓶颈。查看top指标、docker stats 等指标,做并发测试。 import json
import time
import uuid
from concurrent.futures import ThreadPoolExecutor, as_completed
import requests
import threading
class MaxKB:
def __init__(self, protocol, host, port, access_token):
self.token = access_token
self.application_profile = None
self.sender_chat_dict = {}
self.protocol = protocol
self.host = host
self.port = port
self.base_url = f"{protocol}://{host}:{port}"
def profile(self):
"""
获取 应用信息
"""
if self.token is not None:
while True:
result = requests.get(f"{self.base_url}/api/application/profile", headers={"Authorization": self.token})
if result.status_code == 200:
self.application_profile = json.loads(result.content.decode('utf-8'))['data']
break
elif result.status_code == 401:
time.sleep(1) # 避免频繁请求
else:
raise Exception(f"获取应用信息失败,状态码:{result.status_code}")
def open(self, sender_id):
"""
打开会话
"""
if self.application_profile is None:
self.profile()
if self.token is not None and self.application_profile is not None:
result = requests.get(f'{self.base_url}/api/application/{self.application_profile["id"]}/chat/open',
headers={"Authorization": self.token})
if result.status_code == 200:
self.sender_chat_dict[sender_id] = json.loads(result.content.decode('utf-8'))['data']
else:
raise Exception(f"打开会话失败,状态码:{result.status_code}")
def chat(self, sender_id, message):
"""
对话
"""
if sender_id not in self.sender_chat_dict:
self.open(sender_id)
if self.token is not None and self.application_profile is not None:
chat_id = self.sender_chat_dict.get(sender_id)
# 设置流式对话
stream = True
try:
result = requests.post(f"{self.base_url}/api/application/chat_message/{chat_id}",
data={'message': message, 'stream': stream},headers={"Authorization": self.token}) # headers={"Authorization": self.token, "Transfer-Encoding": "chunked"})
print(f"Response result: {result}")
if result.status_code == 200:
if stream:
content = ''
buffer = '' # 缓冲区用于处理未完成的JSON
for chunk in result.iter_content(chunk_size=1024, decode_unicode=False):
if chunk:
buffer += chunk.decode('utf-8')
# 按双换行分割事件块
while '\n\n' in buffer:
end_index = buffer.find('\n\n')
event_str = buffer[:end_index]
buffer = buffer[end_index + 2:]
# 提取 data 部分
if event_str.startswith('data:'):
json_str = event_str[5:].strip()
if json_str:
try:
data = json.loads(json_str)
content += data.get('content', '')
except json.JSONDecodeError:
# 如果 JSON 不完整,放回 buffer 继续接收
buffer = json_str + buffer
# 最后检查 buffer 是否有残留内容
if buffer.strip():
try:
data = json.loads(buffer.strip())
content += data.get('content', '')
except json.JSONDecodeError:
pass
return content
else:
return json.loads(result.content.decode('utf-8'))['data']['content']
except Exception as e:
raise Exception(f"对话失败,状态码:{e}")
maxkb = MaxKB('http', '192.168.80.3', '8080', 'application-6aa08ed851406bb578c4bc1c9ca5728e')
executor = ThreadPoolExecutor(max_workers=300) # 根据需要调整最大线程数
def chat():
start_time = time.time()
thread_name = threading.current_thread().name
try:
res = maxkb.chat(str(uuid.uuid1()), '第138题')
print(f"[{thread_name}] chat_results===>{res}")
return (time.time() - start_time, True)
except Exception as e:
print(f"[{thread_name}] Error:{e}")
return (time.time() - start_time, False)
# ========== 新增整体运行时间统计 ==========
start_total_time = time.time() # 记录程序开始时间
results = []
total_time = 0 # 所有线程耗时总和
success_count = 0
failure_count = 0
# 对于3000并发的情况,您可能需要调整max_workers的数量,或者使用ProcessPoolExecutor
#测试300个并发
r = [executor.submit(chat) for i in range(300)]
# 等待所有线程完成,并收集结果
for future in as_completed(r):
execution_time, success = future.result()
results.append(execution_time)
total_time += execution_time
if success:
success_count += 1
else:
failure_count += 1
end_total_time = time.time() # 记录程序结束时间
actual_duration = end_total_time - start_total_time # 实际运行时间
average_time = total_time / len(results) if results else 0
# ========== 输出结果 ==========
print(f"✅ 整体运行时长: {actual_duration:.2f} 秒")
print(f"📦 总任务数: {len(results)}")
print(f"🎯 平均单任务耗时: {average_time:.2f} 秒")
print(f"🟢 成功次数: {success_count}")
print(f"🔴 失败次数: {failure_count}")
持续观察各项指标。 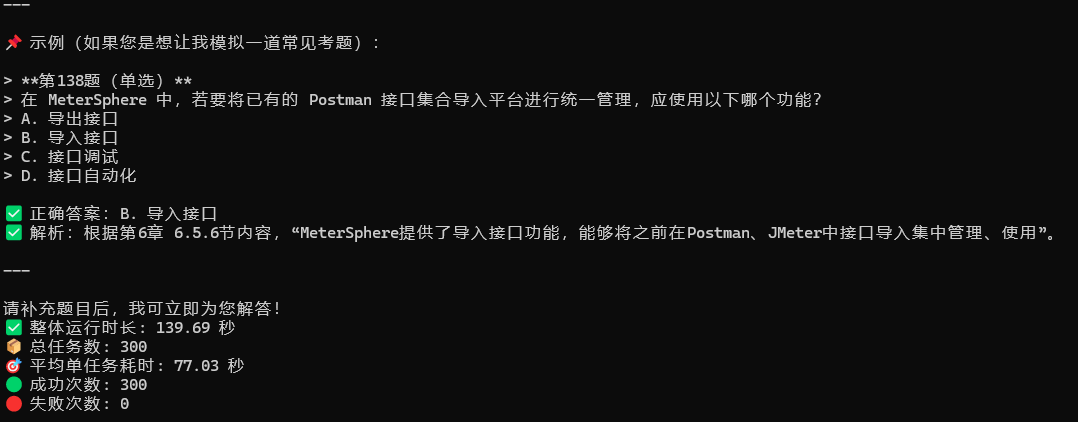

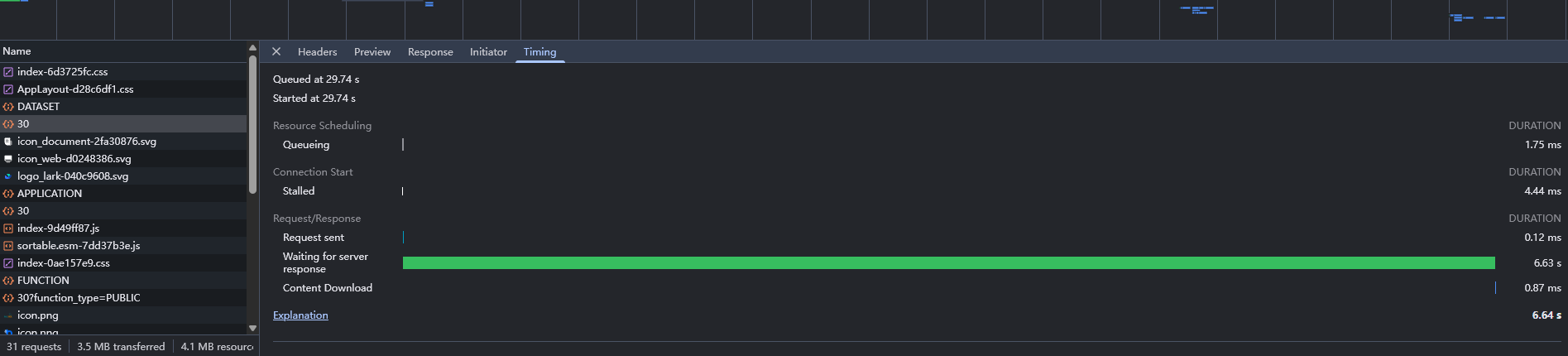
如一下设备为瓶颈,应当适当增加机器的配置。 
|

